






Senza categoria
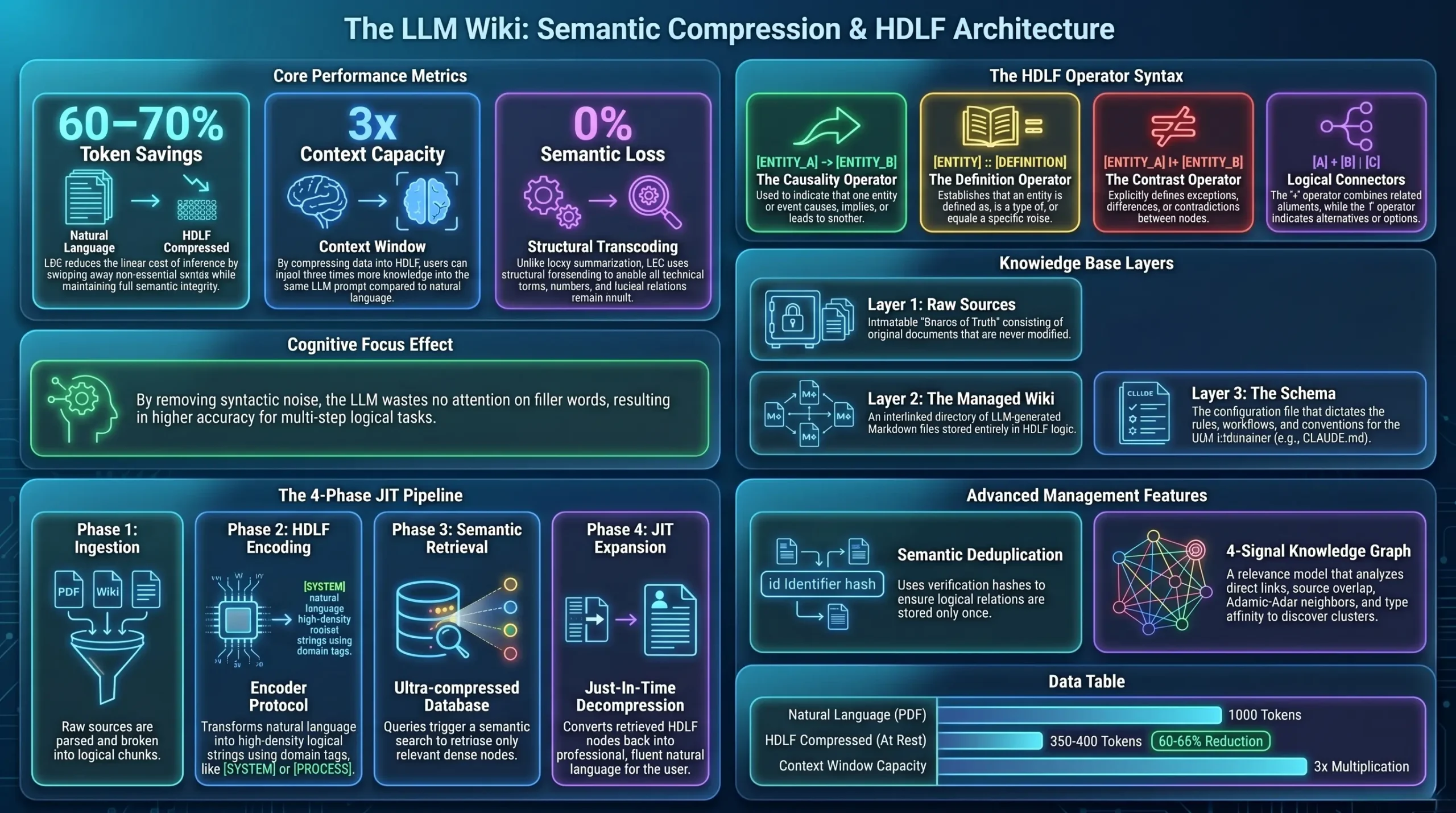
The Cognitive Focus Effect: Why Logic Beats Prose
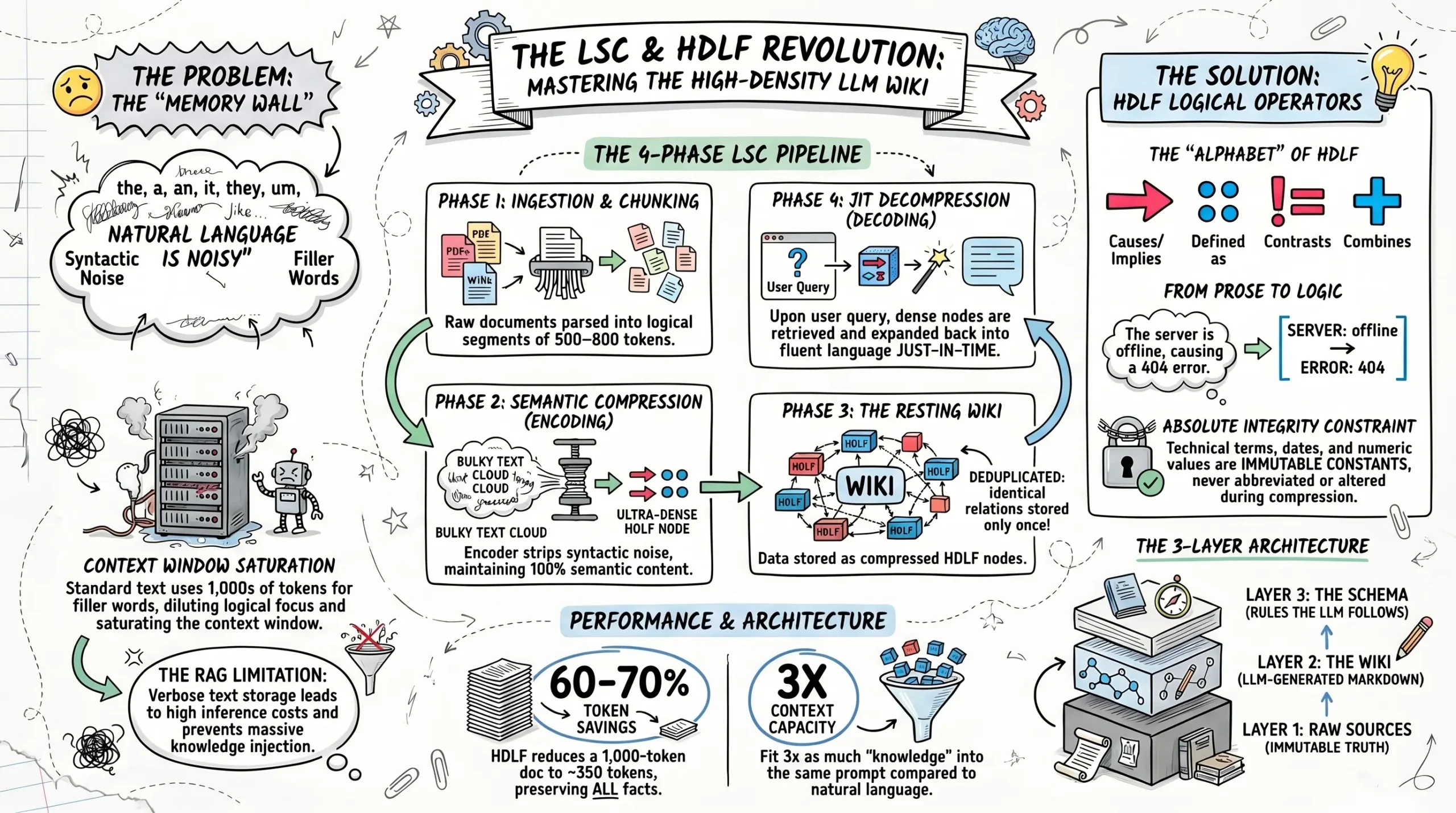
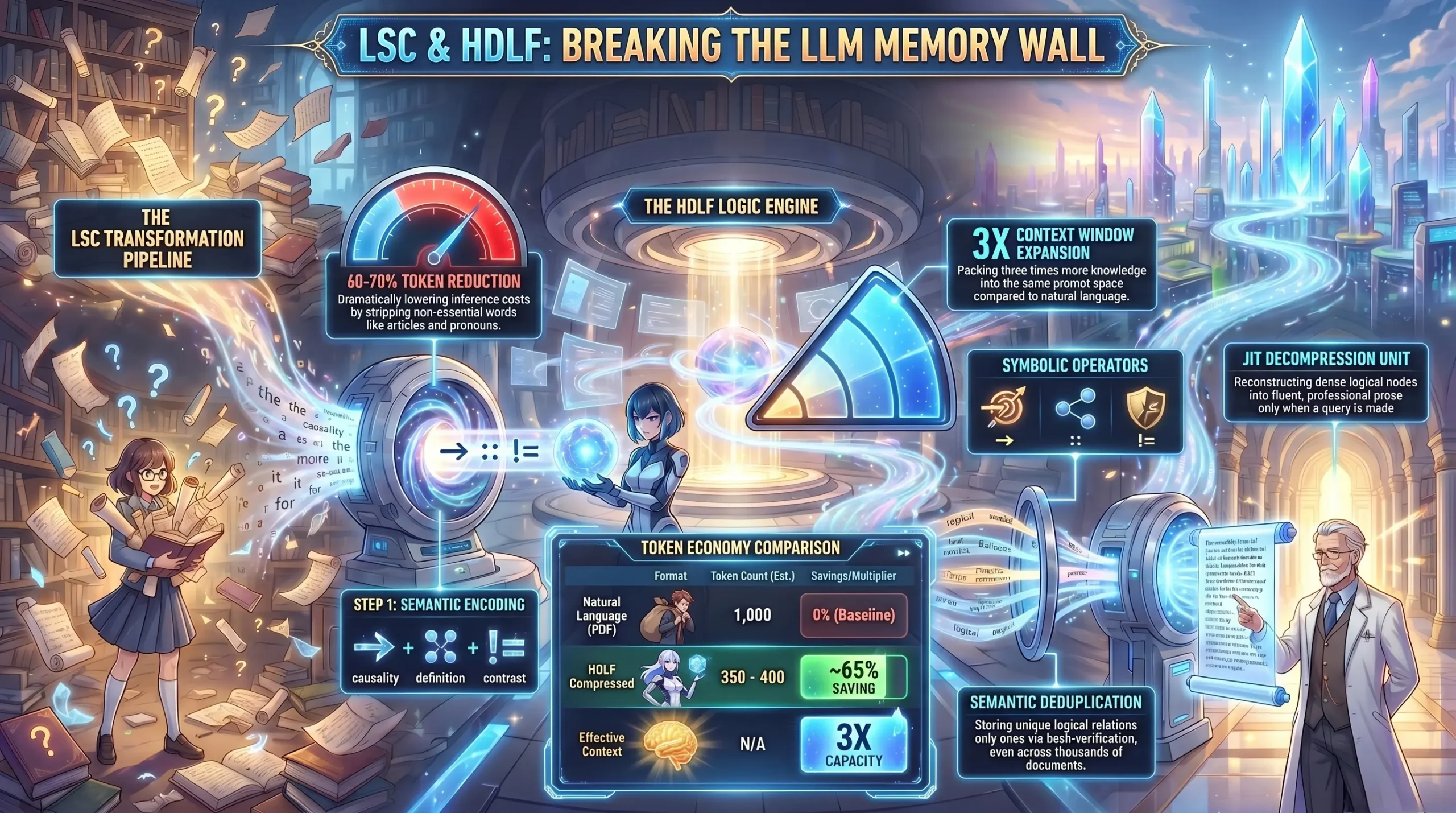
Why LLMs perform better at reasoning when fed compressed logical formats instead of natural language. Efficiency in Reasoning Processing HDLF rather than verbose prose provides a “Cognitive Focus” for the LLM.